
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- R트리맵
- r에서 select
- k최근접이웃
- R시각화
- R데이터싸이언스
- KNeighborsClassifier
- IBK기업은행 #IBK기업은행청년인턴 #기업은행인턴면접후기
- r에서 group_by
- R트리맵문법
- r에서 filter
- r에서 arrange
- dplyr패키지
- R데이터분석
- r
- 머신러닝
- Today
- Total
말랭이의 경제 연구소
머신러닝의 대표 알고리즘-'KNeighborsClassifier(k최근접이웃)' 본문
머신러닝에는 몇 가지 유명한 알고리즘이 있습니다. 오늘은 그중에서도 'kNeighborsClassifier'에 대해 다뤄보겠습니다.
그중에서도 가장 흔한 '생선 분류 문제'를 통하여 KNeighborsClassifier(k최근접이웃)를 알아보겠습니다.
Question. 생선의 길이만 보고도 생선이 어떤 종류인지 알아야한다!
여러 생선 종류가 있으나, 우리는 생선의 길이만으로 생선이 어떤 종류인지 알아야 합니다.
만약, 도미의 길이는 30~40cm정도라고 가정합시다. 그러나, 길이가 30~40cm인 모든 생선이 도미는 아닐 것입니다.
이 문제를 어떻게 해결할까요?
1)일단 도미의 무게와 길이가 있는 데이터를 준비합니다.
데이터:https://gist.github.com/rickiepark/b37d04a95a42ef6757e4a99214d61697
도미의 길이, 무게 데이터
도미의 길이, 무게 데이터. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com

이는 첫번째 도미의 길이는 25.4 cm, 무게는 242kg임을 의미합니다.
위와 같이 숫자 형태로만 있으면 도미의 무게와 길이에 대한 관계 파악이 어려워 그래프를 그리고자 합니다.
2) matplotlib 패키지와 scatter함수를 사용하여 도미의 길이를 x축으로 하고 무게를 y축으로 하는 그래프를 그려보도록 하겠습니다.

scatter는 산점도를 그리는 함수입니다.

도미의 길이가 길수록 무게더 많이 나가네요! 이와 같은 관계를 선형적(linear)이라고 합니다.
빙어도 똑같이 하여 산점도 그래프를 나타내보겠습니다.
https://gist.github.com/rickiepark/1e89fe2a9d4ad92bc9f073163c9a37a7
빙어의 길이, 무게 데이터
빙어의 길이, 무게 데이터. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
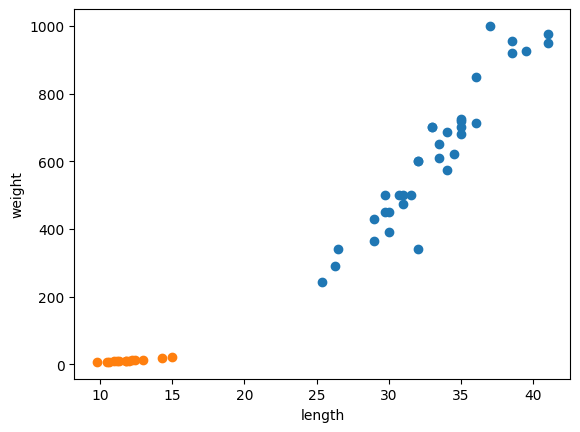
도미는 뚜렷하게 길이와 무게가 선형적 관계를 가졌다고 할 수 있지만, 빙어는 애매합니다.
자, 이제 데이터는 모두 준비되었습니다. 지금부터 'KNeighborsClassifier'을 통하여 생선의 종류를 분류해보도록 하겠습니다.
1)도미와 빙어의 데이터를 길이끼리, 무게끼리 합쳐줘야 합니다.

리스트는 리스트끼리 연산이 가능하므로 위와 같이 합쳐줍니다.
2)도미의 무게,길이/빙어의 무게,길이를 짝지어줘야 합니다.
이 과정을 수행하려면 길이와 무게를 세로 방향으로 늘어뜨린 2차원의 리스트를 이용해야 하는데, 이때 zip() 함수를 사용해야 합니다.

fish_data의 첫번째 원소는 길이가 25.4이고 무게는 242.0인 생선입니다.
이러한 방식으로 도미와 빙어의 데이터가 각각 무게랑 길이로 짝지어져서 fish_data에 저장되어 있습니다.
3)정답 데이터를 준비해야 합니다.
fish_data에서 만든 생선 데이터들이 도미인지, 빙어인지 정답을 알려줘야하기 때문입니다.
도미는 1 빙어는 0이라고 해둡시다. 도미 데이터는 15개를 입력하였고 빙어 데이터는 14개를 입력하였으니 1은 15개 0은 14개 있다고 만들어주면 됩니다.

이제 정말로 훈련 데이터와 정답 데이터가 준비되었습니다.
이제 KNeighborsClassifier 패키지를 불러옵니다.
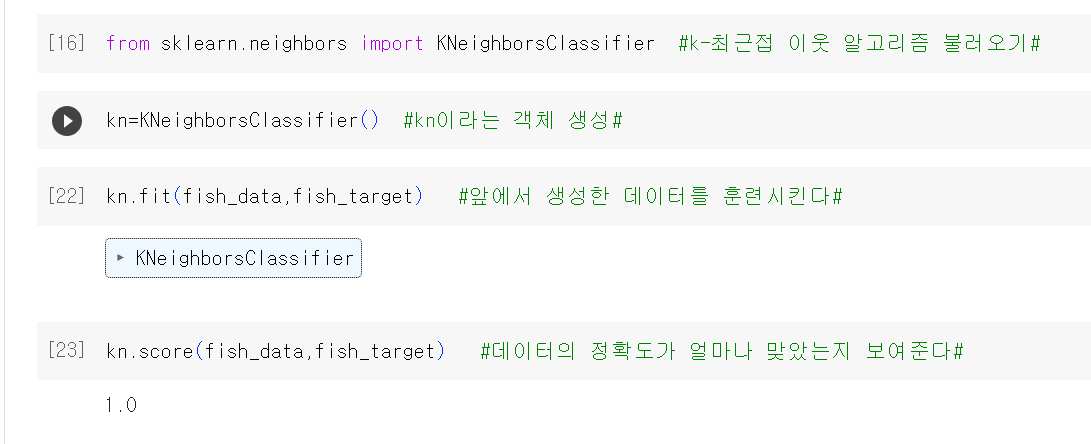
kn.score가 1인 것을 보니 모두 다 정답이네요~!
이제, 새로운 생선 데이터를 넣어 해당 생선이 도미인지 빙어인지 알아보겠습니다.

길이가 30 무게가 600g인 데이터를 넣었더니 [1]이 나왔네요.
아까 1은 도미라고 정의 했습니다. 해당 물고기는 도미네요.
KNeighborsClassifier의 원리는?
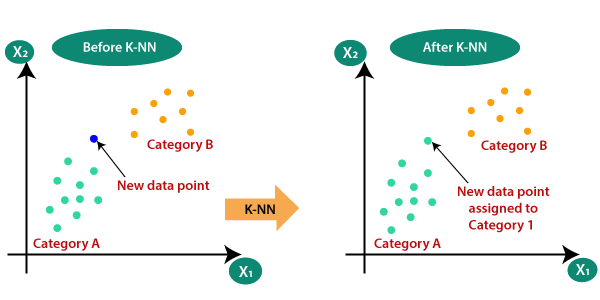
아까 산출했던 산점도 그래프에다 새로운 생선 데이터를 넣으면 해당 데이터가 어떤 생선인지 알려주는 것이 KNeighborClassifer 알고리즘이였습니다.
이 KNeighborClassifier는 주위에 있는 데이터들과 새로운 데이터 간의 거리(정확히 말하면 유클리드 거리) 를 계산하여 해당 데이터가 어느 집단에 더 가까이 속하는지 알려주는 알고리즘입니다.
훈련 데이터와 정답 데이터를 모두 알고 있다면 새로운 데이터가 주어졌을 때 어디에 속하는지 쉽게 알 수 있을 것입니다.